










[성균관대 인터뷰] 휴머노이드 전신 제어·매니퓰레이션 연구, 왜 애지봇 X2 울트라를 선택했을까
2분1409
요즘 휴머노이드 데모는 화려합니다. 백덤블링을 하고, 춤을 추고, 계단을 뛰어오르죠. 하지만 휴머노이드 전신 제어나 매니퓰레이션을 연구하는 연구실의 질문은 다릅니다. 내 연구 주제에 맞는 플랫폼인가, 하루 수십 번의 반복 실험을 버티는가, 2차 개발 문서와 지원은 충분한가.
올해 성균관대학교의 한 연구실이 마로솔을 통해 연구용 휴머노이드 애지봇 X2 울트라와 모방학습 미들웨어 솔링크 데이터 매니저를 함께 도입했습니다. '최신 로봇'이 아니라 '연구 적합성'을 기준으로 플랫폼을 고른 과정을, 도입 검토부터 실험 환경 구축, 데이터 검수까지 직접 경험한 성균관대학교 로봇 및 지능시스템 연구실 연구원에게 9가지 질문으로 물었습니다.

저희는 휴머노이드의 전신 제어와 매니퓰레이션을 함께 보는 연구를 진행하고 있습니다. 단순히 걷는 것만이 아니라, 실제 작업 공간 안에서 버튼을 누르거나, 물건을 집어 옮기고, 핸들링하는 과업까지 확장해서 보고 있어요.
휴머노이드 연구가 '보행' 따로, '팔 조작' 따로 가던 시기는 지났다고 봅니다. 사람이 일하는 공간에서 쓸모 있으려면 걸으면서 균형을 유지한 채 작업하는 능력이 결국 필요하거든요. 그래서 이족보행 기반 플랫폼이면서 상체 조작 연구가 가능한 로봇이 필요했고, 이번 도입도 그 연구 목적에 맞춰 진행하게 됐습니다.
매니퓰레이션(Manipulation)은 팔과 핸드(그리퍼)로 물체를 집고, 옮기고, 조작하는 모든 과업을 말합니다. 버튼 누르기, 픽앤플레이스, 핸들 돌리기가 대표 연구 태스크입니다. 이족보행 휴머노이드에서는 조작 중 무게중심 변화까지 보상해야 해 난이도가 한 단계 더 올라갑니다.

연구용 플랫폼을 고를 때는 화려한 데모보다 실제 연구에 필요한 조건을 보게 됩니다. 데모는 그 제조사가 가장 잘 통제한 환경에서 찍은 '베스트 컷'이잖아요. 저희 연구실 환경에서, 저희 태스크로, 매일 반복했을 때 어떤지는 별개의 문제입니다. 저희는 크게 세 가지를 봤습니다.
덧붙이면, 이 세 가지는 저희 연구실 기준이고, 연구 주제가 다르면 기준도 달라져야 합니다. 보행 자체를 본다면 관절 토크와 제어 주기가, 모방학습 중심이라면 데이터 파이프라인 구축 가능성이 1순위가 되겠죠.

여러 모델을 비교해봤지만, 저희 연구 목적과 가장 잘 맞는 모델은 애지봇 X2 울트라였습니다. 보행과 함께 버튼 누르기, 물체 이동, 핸들링 같은 매니퓰레이션 연구를 염두에 두고 있었기 때문에 상체 활용성과 페이로드, 개발 확장성을 중요하게 봤고, 이 부분에서 X2 울트라가 가장 부합했습니다.

의외로 결정에 영향을 준 게 발열이었어요. 일부 휴머노이드 모델은 장시간 구동하거나 연구 환경에서 반복 실험을 돌릴 때 발열 이슈가 신경 쓰이는 경우가 있습니다. 발열이 누적되면 관절 출력이 제한되거나 실험을 중간에 끊고 쿨다운을 기다려야 하는데, 그게 쌓이면 하루에 돌릴 수 있는 실험 횟수 자체가 줄어들거든요. 애지봇 X2 울트라는 그런 측면에서 상대적으로 안정적이라는 점이 기존 인프라와도 잘 어울렸습니다.
연구실에서 휴머노이드를 도입할 때는 제품 하나만 보는 게 아니라, 앞으로 연구를 어떤 방식으로 확장할 수 있을지까지 함께 고려하게 됩니다. 장비는 한 번 사면 몇 년을 쓰는데, 그 사이 연구 주제는 계속 진화하니까요.
그런 점에서 마로솔이 단순한 견적 안내에 그치지 않고, 휴머노이드 매니퓰레이션과 실증, 환경 구축과 관련된 실제 사례와 방향성을 함께 설명해주신 부분이 큰 도움이 됐습니다. "이 모델은 이런 연구실에서 이렇게 쓰고 있다"는 레퍼런스가 있으니, 저희 상황에 대입해 판단하기가 훨씬 수월했어요.
또 기술 문서나 개발 관련 자료, 이후 연구 진행에 필요한 가이드까지 폭넓게 연결해주셔서, 휴머노이드 선정과 개발·실험 환경을 검토하는 초기 단계에서 판단의 기준을 잡는 데 유용했습니다. 특히 도입 단계에서 모방학습 데이터 수집 환경까지 묶어서 제안해주신 게 결과적으로 시간을 가장 많이 아껴준 부분이었고요.

맞습니다. 연구에서는 장비를 도입하는 것보다 실제 실험을 빨리 시작할 수 있는 환경을 만드는 게 더 중요할 때가 많습니다. 로봇이 연구실에 도착한 날과 첫 실험 데이터를 얻은 날 사이의 간격, 그게 연구실의 진짜 비용이에요.
특히 휴머노이드 모방학습은 실험 준비와 데이터 수집 과정이 복잡합니다. 휴머노이드는 한 대의 로봇이라기보다 여러 시스템이 동시에 살아 움직이는 환경에 가까워요. VR에서 들어오는 손 동작, 그걸 받아 움직이는 수십 개의 관절, 로봇이 보는 카메라 영상까지 — 이 모든 데이터가 같은 시간 기준으로 맞물려야 비로소 학습에 쓸 수 있는 데이터가 됩니다.
이 사이를 잡아주는 레이어가 없으면 연구자는 본 실험을 시작하기도 전에 IK(역기구학) 설정, 장비 간 통신 브릿지, 밀리초 단위 시간 동기화, 에피소드 저장 구조까지 전부 직접 만들어야 합니다. 이 미들웨어를 연구실이 자체 개발하면 6개월씩 걸리는 경우가 적지 않다고 들었는데, 충분히 공감되는 숫자예요.
점심 : VR·로봇·카메라를 묶는 통신 브릿지 연결(ROS·TCP/IP·UDP 프로토콜이 제각각)
오후 : 카메라 영상과 관절값이 밀리초 단위로 어긋나지 않게 시간 동기화 코드 수정
저녁 : 데이터를 에피소드 단위로 저장하는 구조 구현
정작 하고 싶었던 본 연구, "어떤 작업을 시연시키고 어떤 모델로 학습시킬까"는 하루가 끝나도 시작하지 못합니다.
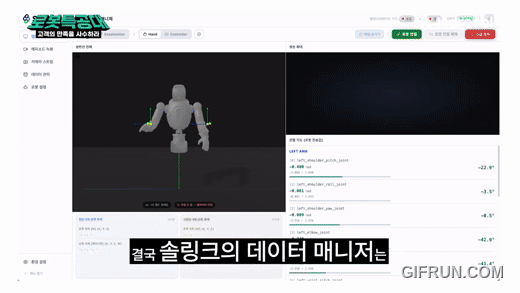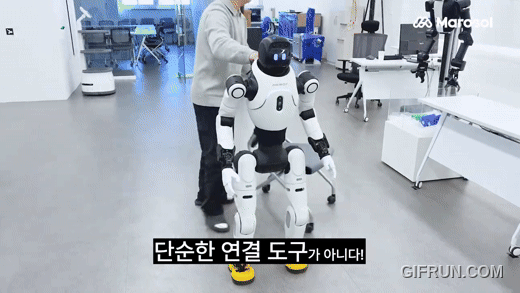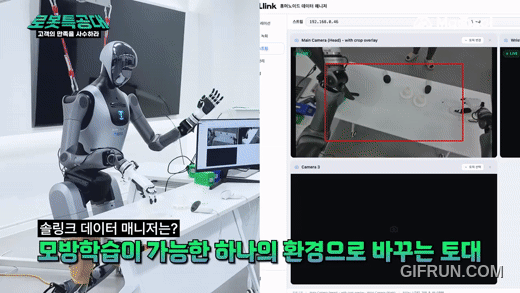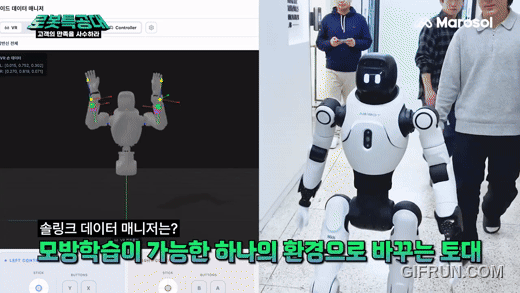
마로솔이 제공한 솔링크 데이터 매니저는 이 과정을 훨씬 단순하게 만들어줍니다. 로봇 연결, 필요한 설정, 데이터 기록까지 하나의 흐름으로 이어주기 때문에, 연구자가 환경 구축에 시간을 쓰지 않고 실제 실험과 학습에 더 빨리 들어갈 수 있다는 점이 인상적이었습니다.
로봇 타입 선택
네트워크 연결
수집 항목 정의
디바이스 활성화
실험 시작
실제 사용 흐름도 단순합니다. 환경 설정 화면에서 로봇 타입과 IP를 등록하고, 어떤 데이터를 모을지 토픽 프로필을 만들고, 디바이스를 브릿지에 연결하면 끝이에요. 코드 한 줄 없이, 며칠 걸리던 준비가 몇 번의 클릭으로 줄어듭니다. 프로필을 한 번 만들어두면 연구실의 다른 멤버가 실험을 이어가도 동일한 환경에서 출발할 수 있다는 점도 연구실 입장에선 중요한 포인트입니다.

흐름은 이렇습니다. 연구자가 Meta Quest VR 헤드셋을 쓰고 손을 움직이면, 솔링크 미들웨어가 손 동작을 IK로 변환해 애지봇 X2의 손 관절로 보냅니다.
화면에는 3D로 시각화된 휴머노이드가 같은 동작을 따라 하고, 손 추적 패널과 관절 디버그 정보가 로봇 상태를 실시간으로 보여줘요. 처음 보면 신기하고, 쓰다 보면 디버깅 시간이 줄어드는 게 진짜 가치라는 걸 알게 됩니다.
데이터 수집은 더 단순합니다. 에피소드 녹화 탭에서 시작 버튼을 누르고, 작업을 시연하고, 정지 버튼을 누르면 — 로봇 시점의 카메라 영상, 각 관절의 움직임, VR 입력값이 같은 시간 기준으로 묶여 하나의 에피소드로 저장됩니다. 이 사이클을 수백 번 반복하면 그게 곧 모방학습용 데이터셋이 되는 거죠.
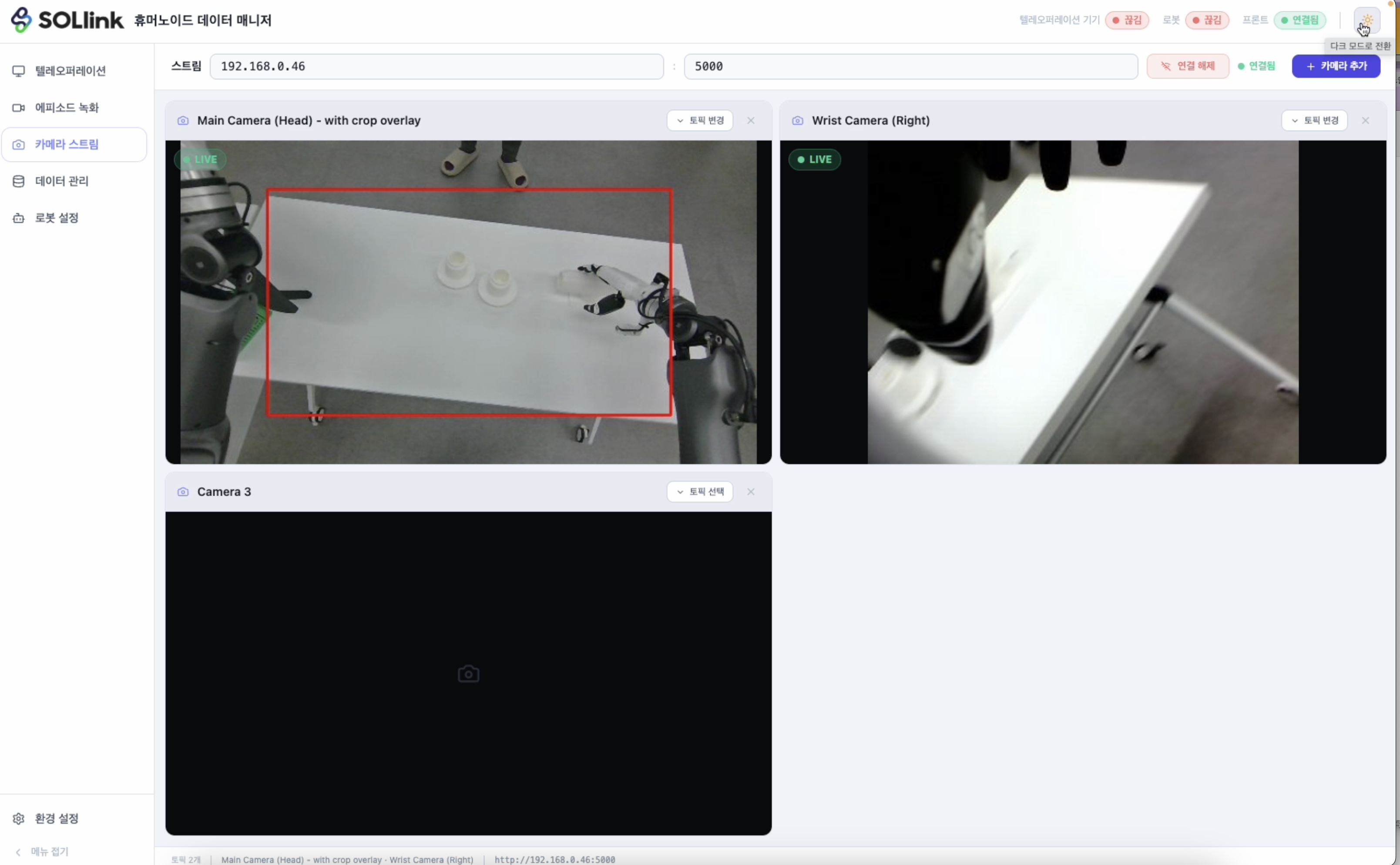
가장 만족스러운 건 실시간 카메라 스트림 검증입니다. 휴머노이드 모방학습에서 로봇 시점 영상은 단순 모니터링 화면이 아니라, 나중에 학습 모델이 그대로 입력으로 받아들일 데이터 그 자체거든요. 잡음이 끼거나 각도가 어긋나거나 관절값과 시간이 미세하게 틀어지면 그 에피소드는 통째로 폐기 데이터가 됩니다.
데이터 매니저는 수집하는 그 순간 화면에 스트림을 띄워주기 때문에, 시연 도중에 데이터 품질을 그 자리에서 바로 검증할 수 있어요. 수백 건을 다 모은 뒤에야 "한 통이 전부 못 쓰는 데이터"라는 걸 발견하는 사고를, 이 한 화면이 막아줍니다. 데이터 관리 탭에서 쌓인 에피소드를 목록으로 보고, 특정 순간의 이미지와 관절값을 나란히 다시 확인할 수 있는 것도 학습 전 마지막 품질 점검에 유용하고요.
모방학습 데이터는 모으는 게 절반, 검증하는 게 나머지 절반입니다.
모방학습에서 모델이 배우는 건 결국 "로봇이 무엇을 보고, 그 순간 어떤 행동을 했는가"의 인과관계인데, 영상과 관절값의 시간축이 조금이라도 어긋난 데이터로 학습하면 모델이 잘못된 인과관계를 배우게 되거든요. 그래서 저희는 데이터 매니저 안의 두 화면으로 검수합니다.
① Data Viewer : 학습용 에피소드를 프레임 단위로 재생하며 검수
수집이 끝난 에피소드를 영상처럼 재생하면서 보는 화면입니다. 예를 들어 152프레임짜리 시연 데이터라면, 그중 96번째 프레임에서 멈춰놓고 그 순간의 카메라 영상과 관절 데이터를 함께 뜯어볼 수 있어요.
왼쪽 영역에서는 데이터 수집 시 설정한 카메라 토픽 중 원하는 영상을 선택해 프레임 단위로 확인할 수 있습니다. 특정 예시 데이터처럼 좌우 카메라가 함께 수집된 경우에는 두 영상을 나란히 보며 비교할 수도 있고요.
오른쪽 영역에서는 action.npy, observation.npy처럼 수집된 관절 데이터 파일을 그래프로 불러와 같은 시간축 위에서 확인합니다. 필요에 따라 1개 또는 2개의 그래프를 선택해 볼 수 있는 구조예요.
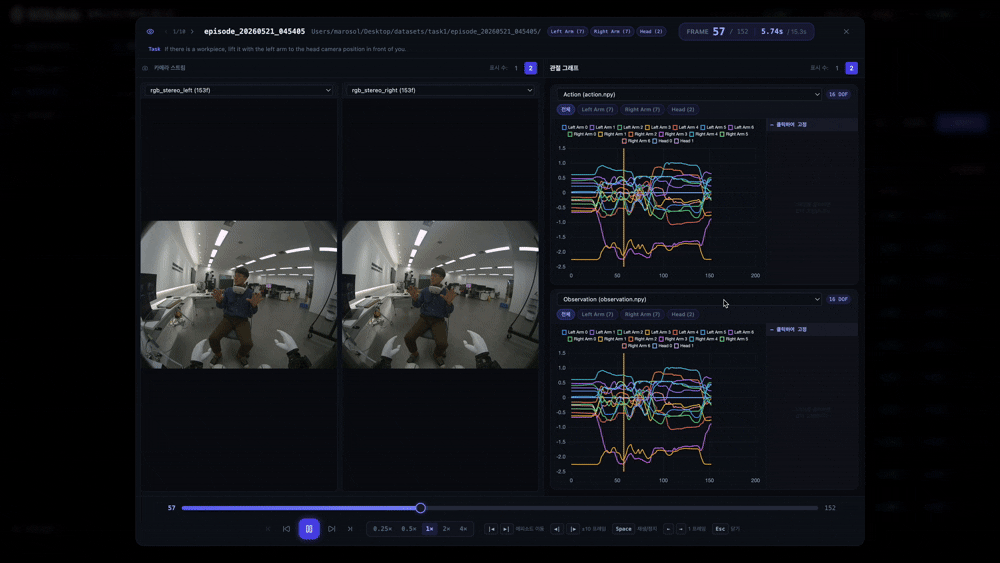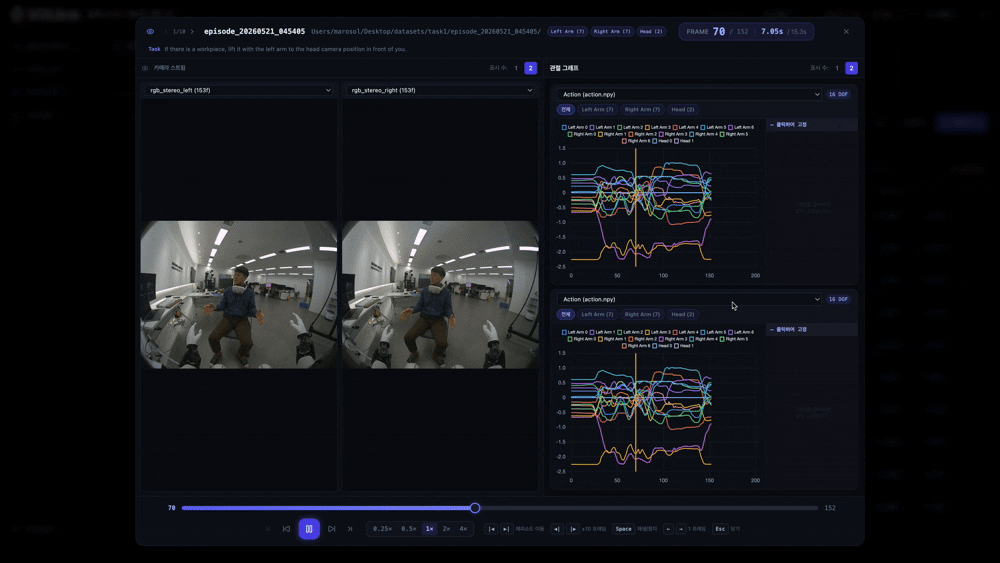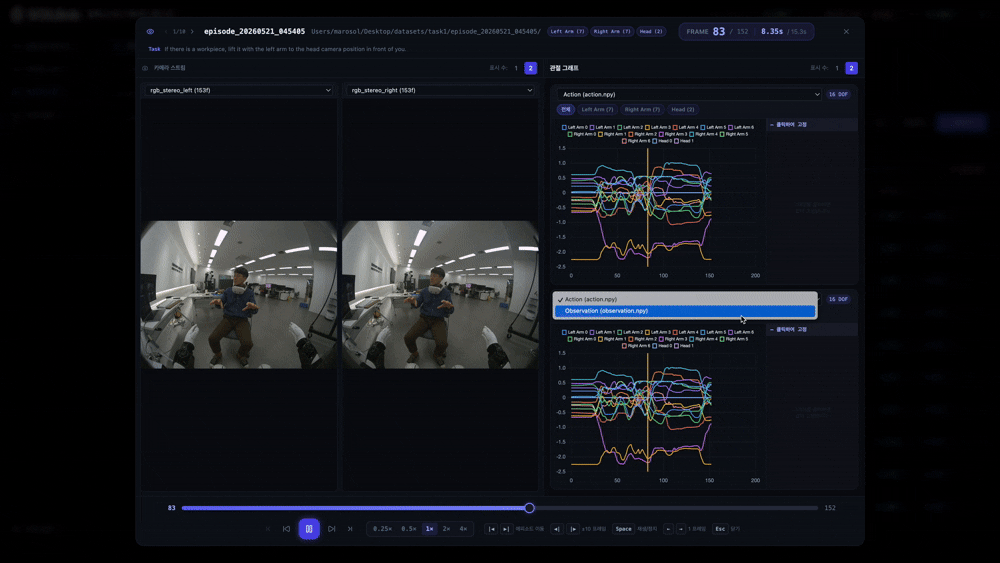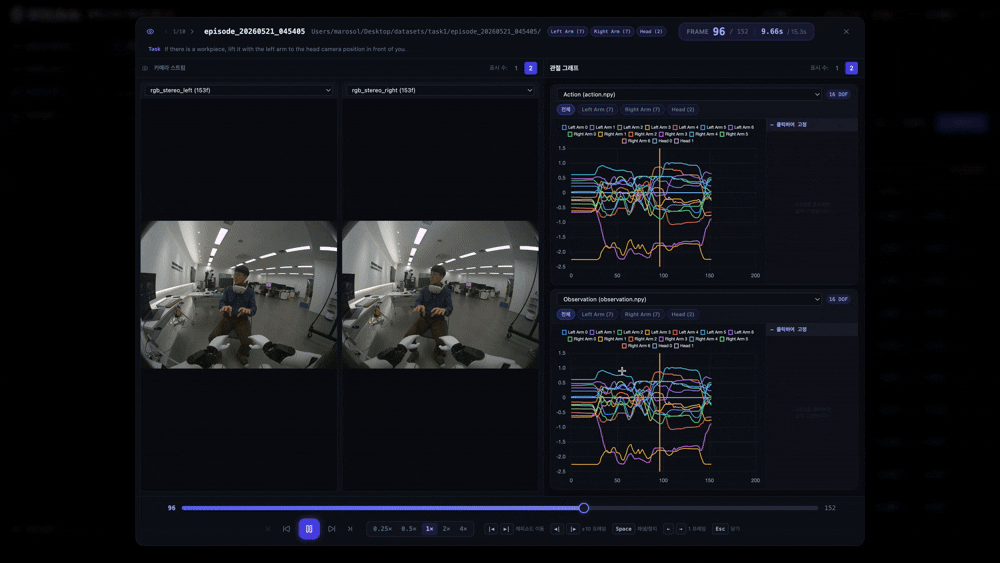
Action은 모델이 학습해야 하는 행동 명령값, Observation은 그 순간 로봇이 관측한 상태값이라고 이해하면 쉽습니다. 예시 데이터에서는 왼팔 7축, 오른팔 7축, 머리 2축까지 총 16개 자유도(DOF)의 값이 표시됐는데요. 이 DOF 수는 에피소드 플레이어의 고정 스펙이 아니라, npy 파일의 shape와 데이터 수집 시 설정한 토픽에 따라 동적으로 달라집니다.
그리고 노란 세로선은 지금 보고 있는 프레임의 위치를 나타냅니다. 그러니까 이건 단순한 영상 플레이어가 아니라, 영상 속 장면과 행동·관측 데이터가 같은 시간에 맞게 움직이는지 확인하는 검수 화면입니다. 영상에서 팔이 움직이는 순간 그래프의 관절값도 함께 변하는지, 한 화면에서 눈으로 확인할 수 있어요.
② HDF5 Viewer : 원본 데이터 파일의 내부 구조를 직접 확인
두 번째는 수집된 원본 데이터 파일, 즉 trajectory.hdf5를 열어 내부 구조와 품질을 직접 확인하는 화면입니다. 파일 안에는 카메라 이미지, 관절 위치값, 타임스탬프, 메타데이터처럼 한 번의 시연에서 나온 데이터가 트리 구조로 정리돼 있어요.
HDF5 뷰어의 장점은 이 원본 데이터 안에 어떤 데이터셋이 들어 있는지 직접 열어보고, 필요한 항목을 선택해 비교할 수 있다는 점입니다. 화면 위쪽에서는 사용자가 각 슬롯에서 원하는 이미지 데이터셋을 직접 선택해 나란히 확인할 수 있습니다. 예를 들어 한 슬롯에는 컬러 이미지 데이터셋을, 다른 슬롯에는 Depth 이미지 데이터셋을 선택하면 같은 에피소드 안에서 장면 정보를 비교해볼 수 있어요.
아래쪽 그래프에서는 파일 안에 저장된 관절 데이터를 선택해 확인합니다. 예컨대 [398×7]이라고 표시된 데이터는 ‘398개 프레임 × 7개 관절’, 즉 7축 팔의 각 관절값이 시간에 따라 어떻게 저장됐는지를 뜻합니다.
파일 안에 조종자 쪽 master 데이터와 실제 로봇 쪽 puppet 데이터가 함께 저장돼 있는 경우에는, 사용자가 각 그래프 슬롯에서 해당 데이터를 선택해 같은 화면에서 비교할 수 있습니다. 다시 말해 HDF5 뷰어가 자동으로 master와 puppet을 구분해 보여주는 방식이라기보다, 원본 파일 안에 존재하는 경로와 데이터셋을 사용자가 직접 선택해 검수하는 구조에 가깝습니다.
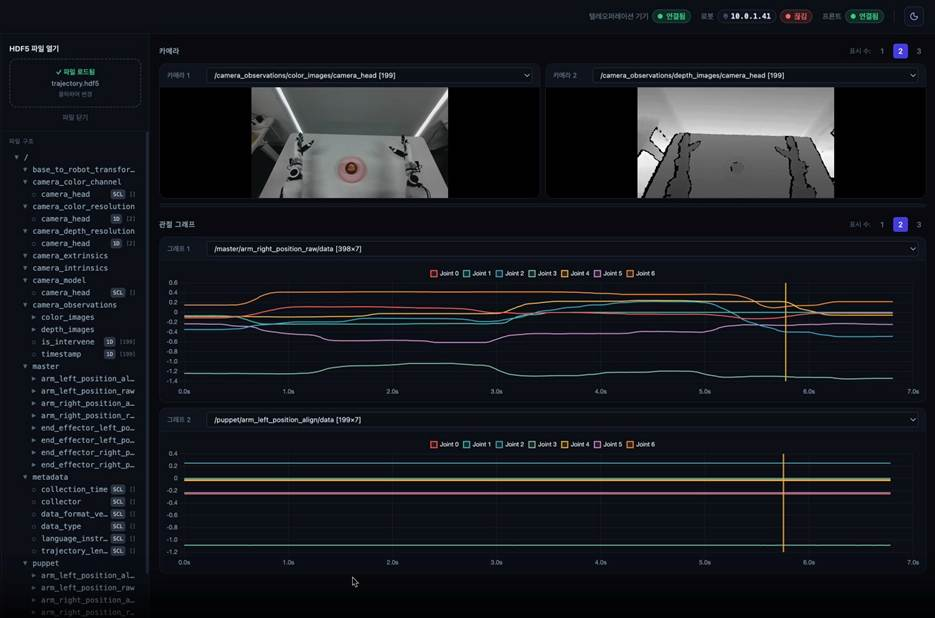
master는 텔레오퍼레이션 조종자(시연자) 쪽 장치의 데이터, puppet은 명령을 받아 실제로 움직인 로봇 쪽 데이터를 가리킵니다. 이 둘과 카메라 영상이 같은 시간축 위에 정확히 맞아야 모방학습 모델이 "이 장면에서는 이렇게 팔을 움직이면 되는구나"를 올바르게 배울 수 있습니다.
비유하자면 HDF5 뷰어가 녹화된 원본 파일의 내부를 열어보는 '파일 검사실'이라면, 에피소드 플레이어는 그 데이터를 학습용 에피소드로 재생해보는 '플레이어 겸 검수실'이에요. 예전 같으면 검증 스크립트를 따로 짜고 그래프를 일일이 그려봐야 했을 일이, 지금은 두 화면에서 끝납니다. 폐기될 데이터를 학습 직전이 아니라 수집 단계에서 바로 걸러낼 수 있다는 것, 수백 건 단위로 데이터를 쌓는 연구실에는 이게 정말 큰 차이입니다.
우선은 애지봇 X2 울트라로 전신 제어와 매니퓰레이션 태스크의 시연 데이터를 쌓는 것이 1차 목표입니다. 버튼 조작이나 픽앤플레이스처럼 정의가 명확한 과업부터 시작해서, 점차 복합 과업으로 넓혀갈 계획이에요. 요즘 피지컬 AI와 VLA(Vision-Language-Action) 모델 쪽 흐름을 보면, 결국 휴머노이드 연구의 경쟁력은 얼마나 빠르게, 얼마나 깨끗한 시연 데이터를 쌓느냐에서 갈린다고 보거든요.
장비 확장도 미리 고려했습니다. 보통 연구실에서는 로봇 기종이 하나 바뀌면 IK부터 저장 구조까지 전부 다시 짜야 해서 '로봇 한 대 = 시스템 한 벌'이 되기 쉬운데, 솔링크 데이터 매니저는 애지봇 X2든 Walker e든 Unitree든 기종이 달라도 동일한 UI, 동일한 워크플로로 운영됩니다. 나중에 다른 기종을 추가 도입하더라도 지금 익힌 워크플로와 쌓아둔 토픽 프로필을 그대로 쓸 수 있다는 건, 연구실의 미래 비용을 미리 줄여둔 셈이라고 생각해요.
휴머노이드는 단순히 '최신 로봇'이라서 도입하기보다, 내가 하려는 연구에 맞는 플랫폼인지를 먼저 보는 게 중요하다고 생각합니다. 보행을 볼 건지, 매니퓰레이션을 볼 건지, 시뮬레이션까지 포함한 파이프라인을 만들 건지에 따라 기준이 완전히 달라지거든요.
결국 연구는 반복 가능성과 확장성이 중요하기 때문에, 하드웨어 스펙만이 아니라 개발 문서, 지원 체계, 그리고 연구 환경 구축 가능성까지 함께 보시면 좋겠습니다. 저희처럼 모방학습을 염두에 둔다면 데이터 수집 파이프라인을 어떻게 만들지를 장비 선정 단계에서 같이 결정하는 걸 권하고 싶어요. 로봇 따로, 환경 따로 가면 그 사이의 간극을 메우는 데 한 학기가 갑니다.
연구에 맞는 휴머노이드 모델이 고민되거나, 연구 환경을 빠르게 구축해 바로 연구에 착수하고 싶다면, 마로솔처럼 관련 경험과 지원 체계를 갖춘 곳에 문의해보는 것도 좋은 방법이라고 생각합니다.

이 글을 읽은 분들이 아래의 포스팅을 좋아합니다




지금 이 로봇 가격 협의 가능!
회원님, 지금 문의하시면 도입 조건에 따라 추가 할인이 있을 수 있어요 💡